New URL: http://blog.joecheng.com
New RSS: http://blog.joecheng.com/index.rdf
See you there!


New URL: http://blog.joecheng.com
New RSS: http://blog.joecheng.com/index.rdf
See you there!
This blog is now coming to you from my brand new virtual private server (VPS), hosted by vpscenter.com.
I'd never heard of VPS, but it seems to be all the rage in the web hosting business--and rightfully so. VPS gives you root access to your own virtual Linux machine, so you get just about all of the control and flexibility of running your own physical server: you can add your own Apache modules, install new languages (like Ruby!), run a J2EE app server, provide IMAP access, schedule jobs, create users... whatever.
Unlike running your own physical server, though, VPS is dirt cheap. We're talking $20/month cheap, compared to $10 for shared hosting and, say, $100 for a dedicated server (and that's not counting the cost of the server itself!). I'm guessing most VPS hosting companies deploy dozens if not hundreds of virtual Linux instances on each skinny little 1U server; the incremental cost of each additional VPS account follows the economies of shared hosting, not the economies of dedicated servers.
The downside, of course, is that you don't get a 2.6GHz of that Xeon and all 4GB of fancy ECC RAM all to yourself--you have to share it with all the other customers on that particular server. Really, though, how many sites need more than 2% (on avg) of a modern server's CPU time?
Every VPS provider I've seen also throws in friendly web-based control panel software that make it easy for you to play webhost to your friends or customers--just a few clicks through a wizard interface and the software automatically configures a new virtual host in Apache, creates the appropriate FTP, shell, and e-mail accounts, and makes the relevant changes to the VPS provider's DNS servers. Luckily, VPS providers generally don't charge you per virtual host, and many don't set any artificial limit on how many virtual hosts you can have.
As of tonight I'm running Resin (with jikes and JDK 1.4.2) on my VPS. I'm planning to run an rsync daemon for backup purposes. mod_python came pre-installed, but not mod_ruby, which I'll have to remedy. It still amazes me that I can say all that about a $20/month account!
Frankly, I don't see why any serious web developer would get a traditional web hosting account these days--VPS gives you so much for so little, it's too good a deal to pass up!
Like most programmers, I'm far from a cryptography expert. That's why I'm so excited about the cryptographic services provided by both the .NET Framework (System.Security.Cryptography) and the Java platform (Java Cryptography Extension). Right out of the box, both give you easy and accessible libraries for doing symmetric and asymmetric encryption, one-way hashing, and digital signatures.
Thanks to these libraries, you don't need to have a very deep understanding of cryptography to begin using it to help secure your applications. You don't need to understand how or why one-way hashing or asymmetric encryption work; you just need to understand where and why you would want to use each one.
If you're a Java or .NET programmer and you're unfamiliar with (or intimidated by) cryptography, take a look at this intro at MSDN. Practically every serious developer should have an understanding of these concepts, especially since the tools are already sitting there in your classpath or GAC, just waiting to be used!
My parents were nice enough to get me a DVD burner for Christmas. So far it's been working great; very fast with both DVD+RW and CD-R (the only two media I've tried so far). And as a bonus, it's far quieter than my aging PlexWriter 12/10/32.
Several other toys have caught my eye lately. One is the Echo Indigo, a CardBus sound card that supports 24/96 playback and has incredibly good specs. At work, I've got my poor 580's plugged directly into my laptop's headphone jack, and it sounds terrible--very audible line noise and distortion. Seems like the Indigo, on the other hand, would do justice to even very high quality headphones. At $130, it's even a decent value, though I'm not sure I personally could justify buying it over the cheaper, less elegant alternatives [1, 2].
The next is VIA's new(?) P4-ITX motherboard, which supports most P4 or Celeron processors and includes S-video out, USB 2.0 ports, optional FireWire support, network adapter, and a PCI slot, all in an area smaller than 7" squared! Stick it in one of these and you've got the start of a book-sized PC with some serious grunt.
And finally, in the "Stuff I'll Never Own" category, Meridian, one of my favorite hi-fi manufacturers, has launched the G Series line of components--and wow. These things are drop dead gorgeous. The G Series is a step up from the already expensive 500 Series, which means these components are well into "Should I buy a lightly used BMW instead?" range. (Scroll to the bottom of this page for the damage.)
Well, Programming Language Pragmatics was too heavy (physically, that is... it's a huge hardcover textbook) for me to read on my commute, so I'll have to try to work through it at work or home.
Now my commute is being spent learning Lisp, via Paul Graham's ANSI Common Lisp. So far it's absolutely excellent. Paul Graham must be one of the most articulate voices in computing. Everything I've read by him (check out his website) has been incredibly well written: interesting, clear, concise, and generally pretty convincing. So far ANSI Common Lisp is the most readable and enjoyable programming language book I've come across, eclipsing my previous favorite: Programming Ruby. The Lisp community is lucky to have this guy as an advocate.
Since my Java-based IMAP server project has been gathering dust since well before the wedding, I thought I'd take another crack at setting up and hosting a Linux mail server out of my apartment. I've never had much luck getting Linux to do my bidding; sure, installing any modern distro is easy and you can boot to a nicely equipped GNOME or KDE desktop without ever firing up a text editor. But once you need to start changing default settings, especially for server stuff... that's where the pain begins. I've always been able to get 80% there, but then something always hangs me up.
Lo and behold... I actually succeeded this time! I've finally got my own Linux mail server: hush.joecheng.com. (It's called "hush" because it's a near-silent machine, using a tiny VIA EPIA board and a very quiet Seagate Barracuda hard drive.)
Unfortunately, my ISP blocks all traffic on port 25 unless it is going to their mail servers. So I actually have all of my mail delivered first to a POP account with my webhost. Hush polls the POP account for messages and then serves them up via IMAP. This is exactly the setup I wanted to support with my own Poorman IMAP server.
To anyone who is familiar with Linux administration, the following will sound like a plain-vanilla ho-hum mail setup. But I suspect it might seem a bit like a Rube Goldberg machine to anyone from the Windows camp! Here are all the programs involved.
Luckily, my Red Hat 9 machine already had all of these programs installed! But I still needed to learn how to configure each of the services.
At first I was a little irritated that so many programs in the chain. But really, this is what the Unix philosophy is all about: chaining together small programs that each do one thing well. The downside is having to learn a ton of small programs. The upside is the incredible amount of flexibility and power you get in return.
I realized that configuring Linux has more in common with programming than it does with configuring Windows. With Windows, you can just click and hunt around until you find the checkbox you're looking for; if you have a general idea of what you're trying to do, it doesn't generally take long to figure out how to do it. With Linux, you really have to spend some time learning the program you're about to configure. Each program has its own set of config files; you probably wouldn't even be able to find them without the docs, much less figure out the configuration syntax. So before you even start touching anything, it's best to take a breath, sit down with a tutorial or the man page, and really spend some time learning about and understanding the program. As a programmer, you wouldn't want to jump in and start playing with the Java 2D API, calling different methods until things work; it's the same with configuring sendmail.
I'm not just trying to present a familiar metaphor here. Traditional Unix programs really are more like APIs than like end user programs on other platforms, and using the shell is very much like interactive programming. So if you're starting out with Linux, understand that for good or ill, you must give system configuration tasks the same kind of attention and respect that you might give programming tasks.
With that in mind, I spent a few nights learning and configuring and learning and configuring. In most cases I only needed to add or modify perhaps a single line to a config file, and often the exact thing I was trying to achieve was specifically addressed somewhere in the documentation. (These programs have been around for a long time; anything you could want to do with them has probably been done thousands of times before.) So this time around, there was very little trial and error involved. I was able to make each change with confidence, and most of the time, it worked the first time.
Fortunately, after all that, it was very much worth the trouble to get it all working. I'm happily using Mozilla Thunderbird 0.4 at home and at work, and I have a consistent view of my mailbox wherever I go thanks to IMAP. I don't have to add mail filtering rules on both clients. I can be sure that when I delete a piece of spam, I'm not going to see it again when I log in from the other computer. And it's all extremely stable, secure, and... free!
print 'how many meters: ' usernumber = gets puts (usernumber.to_f * 3.28).to_s + ' feet'In just a few minutes, she learned about strings, ints, floats, variables, and input/output. I'm married to a genius! :)
AJ and I attended LL3 this past weekend and got to hear some pretty cool ideas.
The first talk (by Dana Moore and Bill Wright) presented Jabber as a way to control distributed software agents. The user fires up a Jabber client and his "buddy list" consists of all the different agents that are floating around the system. He can send chat messages to interact with each one, getting info such as "help", "status", or directives such as "kill cpu" (their project involved agents that attack a distributed system to see how it holds up).
I really like the idea of using Jabber to communicate with "headless" software in general. The usual solution these days seems to involve embedding a web server into the program, or maybe telnet--and that's if the software has a user interface at all. More commonly, input is restricted to config files, environment variables, and command line switches, and the only output you get is a logfile.
Embedding a Jabber client in your program is much lighter weight than embedding a web server: all you need is a client library (the Smack library for Java, for example, weighs in at 124KB, while Jabber4r for Ruby is less than 75KB) and maybe a thread to poll for messages (I assume--I'm not too familiar with the protocol yet). And sending warning or error messages to an administrator through Jabber is much more likely to get attention than if the messages are simply written to a logfile.
I'll refrain from going into any more detail until I've tried this with one of my own projects. If and when I resume development on my IMAP server, I'd like to use Jabber as the interface to add/remove users, reset passwords, and other administrative tasks.
Programming Language Pragmatics has been a great read so far. I'm still in the opening chapters, but already I've gained a better appreciation for the amount of variety that exists in programming languages out there. Such a seemingly simple thing as binding values to variable names can differ quite a bit from one language to the next.
Take Python and Ruby, which are very similar in many important ways: interpreted, dynamically typed, "object oriented". Check out these two snippets:
# Python code def test(): print x x = 1 test() # Ruby code def test() print x end x = 1 test()
Even though the code looks almost identical, you get two very different results. The Python code prints 1; the Ruby code throws the error NameError: undefined local variable or method `i' for main:Object. The reason for this is that Python scopes are dynamic and Ruby scopes are static. Depending on your programming background, you may find one or the other very hard to get used to!
This is just a simple example, but it illustrates the kind of subtle differences that make one language "feel" right to some people but not others.
A more fundamental concept I've learned about is "programming without side-effects", which seems to come from the functional programming world. Programming without side-effects means that when you call a function, the only variables that matter are the inputs, and the only effect of the function is returning a value. In other words, given a set of inputs, you must always get the same answer--the answer can't vary over time, or based on the state of a database record, or whatever. It also means the function must not change the state of the world at all, so calling or not calling the function cannot change the behavior or result of some other function.
Why put these restrictions on functions? What's wrong with side-effects? Well, it turns out that if you can count on a function to be side-effect free, you can be less careful when using it. You can cache results without worrying about them becoming stale. You can skip executing it without having to prove the program is still correct. There is guaranteed to be no coupling between one function call and any other function calls that come before or after. For example, imagine your program contains this statement for logging:
if (DEBUG)
print("DEBUG: Window handle: " + getHandle(window));
Let's say the getHandle function is not side-effect free. On the contrary, it will create a handle for the window if one does not exist. You should be nervous about removing this logging statement--what if the next line of code implicitly assumes that the window already has a handle? But if getHandle could be guaranteed side effect free, there is no way removing the logging call could change the behavior or your program. (Well, actually print itself is not side effect free.)
That's not to say I'm going to go to work tomorrow and start programming without side-effects; far from it. While there are functional languages that encourage or even require your code to be completely side effect free, it's hard to imagine trying to achieve that in a real world Windows app written in C#; most objects are inherently stateful. But recognizing the value in programming this way will help me write better libraries by avoiding side-effects where possible.
The bottom line is that there is great value in studying different programming languages, even if you never adopt them as your own.
I'm on the last chapters of High-Performance Computer Architecture by Harold S. Stone, which describes and quantifies many different techniques for increasing the performance of computer systems. As a software programmer with only enthusiast-level knowledge of machine and systems architecture, I found find this book to be a challenging but enjoyable (and very worthwhile) read. If you're interested in the latest processors to come out of Intel, AMD, and IBM labs, but don't know what terms like "superscalar execution" or "8-way set associative cache" mean; or are curious about the difference between big Cray supercomputers and today's desktops; or wonder why 16-processor servers cost much more than 16 times a single-processor server; this book will answer those questions and more.
One thing about the book is that it's somewhat dated: the edition I read was ©1987. However, the principles and techniques taught in the book are still very relevant today. I really enjoyed this book and I imagine most hardcore programmers would too.
I've also just purchased Programming Language Pragmatics by Michael L. Scott, and I can't wait to get started on it. It's a very large and imposing volume that seems to give a pretty comprehensive treatment of the design and implementation of programming languages. Parsing techniques, type systems, variable scoping, instruction-level optimization, it's all in here. There's also a chapter on functional and declarative languages that should be interesting.
Hopefully I can keep my brain from exploding.
I haven't written about zeroconf services lately so I thought I'd follow up on this comment I made about a month ago:
I've got some ideas about how to create a nice high-level C# binding to this. You should be able to take a marshal-by-ref object and just make one API call that says "make this available to everyone on the network."
Let's compare this idea to making an object available to .NET Remoting clients. Start with the following class:
public class MediaLibrary : MarshalByRefObj
{
///
/// .NET Remoting housekeeping--make this a singleton
///
public override object InitializeLifetimeService()
{
return null;
}
///
/// Returns a list of media on this server that
/// matches the given pattern.
///
public string[] ListMedia(string pattern)
{
// ...details, details...
}
///
/// Returns a stream that is the raw file data
/// for the requested media.
///
public Stream GetMediaStream(string path)
{
// ...details, details...
}
}
If you want to make this a marshal-by-ref singleton object, you need to add the italicized text. As you can see, it's not very expensive in terms of extra lines of code you have to add (though having to derive from MarshalByRefObj could obviously be quite invasive if you're building off an existing class hierarchy).
So now we have a class that can be remoted. How do we get the CLR process to start listening for requests? Well, there are a lot of knobs you can turn here, depending on what kind of serialization you want (binary or XML) and what kind of communications protocol (bare TCP/IP sockets or HTTP) or if you want to customize/extend the process. Let's ignore all of that; here is a simple cut-and-paste template for basic binary TCP/IP communication (which is generally what you want anyway when you're not dealing with firewalls or interop):
ChannelServices.RegisterChannel(new TcpChannel(1234));
RemotingConfiguration.RegisterWellKnownServiceType(
typeof(MediaLibrary),
"MediaLibrary.binary",
WellKnownObjectMode.Singleton);
The first line creates a TcpChannel on port 1234 and registers it with the runtime, which will from then on listen for remoting calls on that port. The second line takes our particular class and publishes an instance of it at the URL "/MediaLibrary.binary". Thus, these two lines make a media library available at tcp://hostname:1234/MediaLibrary.binary.
Clients connect to the server like so:
RemotingConfiguration.RegisterWellKnownClientType(
typeof(MediaLibrary),
"tcp://myserver:1234/MediaLibrary.binary");
MediaLibrary remoteLibrary = new MediaLibrary();
The first method call needs to be done just once (per CLR lifetime), and then any call to MediaLibrary's constructor will result in the creation of a MediaLibrary remoting proxy that connects to our server, as demonstrated in the last line. You can bury the first call somewhere in your client startup routine, and after that it all looks like magic. Need a MediaLibrary? Just new one up, don't worry about how it is implemented, pay no attention to the man behind the curtain.
While remoting as I've presented it is convenient, it's not particularly dynamic. The client has to know the server hostname, the port, and the service URI in advance; I suppose this info is usually gleaned from a config file, registry key, or user dialog. That's pretty annoying for something like a media library (well, I don't mind having a static service URI; just the hostname and port). What I really want is to be able to automatically get references to any (and hopefully, something approximating "every") MediaLibrary service on the LAN. Furthermore, I'd like to be able to do it without the user ever explicitly setting up a directory server.
Using the same MediaLibrary class, I want the following API on the server:
void EasyZeroConf.Publish(MarshalByRefObj serviceObj, string serviceUri);
And the following on the client:
object[] EasyZeroConf.Find(Type desiredType, string serviceUri);
The Publish method is simple enough: Take serviceObj and make it available to anyone requesting the service identified by serviceUri.
The Find method is a little less obvious: Search the LAN for serviceUri, and return the results as an array of remoting proxies of type desiredType. Here's an example:
MediaLibrary[] libraries =
(MediaLibrary[])EasyZeroConf.Find(typeof(MediaLibrary), "MediaLibrary");
That should be literally the only two methods most library users should need to get simple zeroconf LAN services, though I can think of many scenarios where more customization would be very desirable. This post is already getting long though.
I'll also save design/implementation details for another time. My day job beckons...
Ever since I started playing with Ruby, I've been dreading the first time I release a Ruby application and have to tell potential users something like, "By the way, to use my little image resizing program, you need to install a complete programming platform." Sure, I've released programs that require the .NET Framework or a JRE, but at least those are pretty mainstream languages. I can at least pretend to believe that, someday, every Windows client will have a recent CLR and JVM.
Turns out there is a nifty free tool called exerb that compiles a Ruby script into an executable that contains not only the script, but also all dependencies from both the core Ruby interpreter and any Ruby modules you load (whether part of the Ruby standard library or not). The end result is a totally self-contained (albeit slightly bloated) .EXE that will Just Work on any reasonably configured Windows machine, without the end user ever having to know about Ruby.
About that bloat... a trivially simple .rb script under 1.8.0 compiled to an .EXE weighing in at almost 0.5 MB. But that's a small price to pay for the convenience of a single program file with no dependencies.
I've decided to call the blog software "whateverblog", since the first blog it will be used for is this one... and because I am not very creative.
Of the three major parts (GUI frontend for editing content; generate website by merging content with templates; checksum-based sync files with web server via FTP), the first part is done and the second part is about half done. That is, the eRuby part of the templating system is written and the C# front-end is set up to interop with it, but I don't currently have a way to manage or choose between different sets of templates.
Still, I'm really excited that the eRuby stuff was so easy to integrate. I simply wrote a standalone Ruby script that reads in the data file, turns it into a nice array of articles, reads the template into memory, then runs the eRuby processor on the template (making the array of articles available to the template). It's great; I can combine the power and expressiveness of eRuby templates with the easy wysiwyg editing of CityDesk (and Contribute and whatnot).
I have a feeling the template management problem could end up being surprisingly difficult. I don't have a clear picture at all about how it should work. Need to let that one stew a little...
Right now I'm using Fog Creek's CityDesk to generate this blog. While CityDesk is a wonderful tool for its intended purpose--allowing the, shall we say, "technically challenged" to maintain website content--its limitations bother me a little. In particular, its proprietary scripting mini-language is way too specialized for my tastes; it can easily handle simple web scripting needs, but then it hits a brick wall.
So, of course, I've decided to write my own blog software. (Yes, I realize that the world needs yet another blog program like it needs a hole in the head. I just can't help myself.) Actually, I didn't decide to write it as a result of CityDesk letting me down, particularly. I was just messing around with Microsoft's DHTML Edit Control and the blog software grew up around it by accident.
Like CityDesk, a simple WYSIWYG interface will be the input method for individual articles. A static website will be generated on disk, using HTML templates impregnated with Ruby code. Said static website will then be synced over FTP to your web server. (Sorry for all the passive-tense. I haven't named the software yet.)
Though the mechanism is, at a high level, almost identical to CityDesk, I am in no way attempting to create a competitor or substitute. CD lets you do some important things that I am not interested in tackling, such as organize your entries in arbitrarily nested folders, create multiple templates, "intelligently" manage links between entities within your site, etc. I currently intend to punt on all of the above. So my program will only really be useful for blogs, or other one-dimensional content.
The first of the three major parts is done: you can create, edit, and delete posts through a Windows Forms (C#) interface. I am using my own simple file format to persist the posts to disk, to make it easy to marshal the data into the Ruby interpreter.
Screenshots coming soon (not that they'll be very exciting).
I sent an e-mail to Don Box asking if the collections API in Whidbey will have Ruby-style iterators over collections, to go with C#'s new support for anonymous methods (aka closures). His entire reply: "Yes it does."
Holy crap... between generics and this, the collection classes in Whidbey are going to rock. I can't wait to do this:
List<Employee> employees = ...
List<int> employeeIds = employees.Collect(delegate(Employee e){return e.Id;});
Now if only there was a C# IDE that could keep up with IntelliJ...
Lately I've gotten used to using Ruby to generate particularly mind-numbing chunks of C# code. For example, if I had to write the following:
// Red Flag flagRed.Name = "Red"; flagRed.Text = "Red"; flagRed.OnSelected += new FlagSelectionHandler(flagRed).Handler; flagRed.Image = "flagRed.jpg"; flags.Add(flagRed); // Blue Flag flagBlue.Name = "Blue"; flagBlue.Text = "Blue"; flagBlue.OnSelected += new FlagSelectionHandler(flagBlue).Handler; flagBlue.Image = "flagBlue.jpg"; flags.Add(flagBlue); // ...and so on for green, yellow, orange, purple...
I can just fire up irb and type the following:
template = <<TEMPLATE // @ Flag flag@.Name = "@"; flag@.Text = "@"; flag@.OnSelected += new FlagSelectionHandler(flag@).Handler; flag@.Image = "flag@.jpg"; flags.Add(flag@); TEMPLATE ['Red', 'Blue', 'Green', 'Yellow', 'Orange', 'Purple'].each do |color| puts template.gsub(/\@/, color) end
and cut and paste the result to Visual Studio. So easy.
I also wanted to share this little bit of Ruby that parses Unicode script data and writes C# code with the result:
require 'net/http'
# get latest script from web
h = Net::HTTP.new('www.unicode.org', 80)
resp, data = h.get('/Public/UNIDATA/Scripts.txt', nil)
if resp.code !~ /^200/
raise "Error code: #{resp.code}"
end
list = []
scripts = []
# the full text is in 'data' var
data.each_with_index do |line, i|
# skip comments and all-whitespace lines
next if line !~ /[^\s]/ or line =~ /^#/
# parse single-point
if line =~ /^([0-9A-F]{4,})\s*;\s*(\w*)/
range = [$1, $1]
script = $2
# parse range
elsif line =~ /^([0-9A-F]{4,})\.\.([0-9A-F]{4,})\s*;\s*(\w*)/
range = [$1, $2]
script = $3
else
raise "Parse error on line #{i + 1}: #{line}"
end
list << [range, script]
scripts << script
end
scripts.uniq! # remove duplicates
# now print C#
list.each do |x|
(low, high), script = x
if (low == high)
puts "scripts.Add(0x#{low}, Script.#{script});"
else
puts "scripts.Add(0x#{low}, 0x#{high}, Script.#{script});"
end
end
puts
puts scripts.join(",\n")
This is the kind of thing at which Ruby really excels: banging out one-off text processing apps.
There's something neat about the fact that you can plunk down $100 (or $250, or $500 if you're a real high roller) and completely change the look of your computer. Too bad you can't do that with a car.
Yesterday I replaced my Lian-Li PC60 with a (just discontinued) Cooler Master ATC-710-GX2 in dark grey. The PC60 is sort of a classic. It was the case that, along with the Cooler Master ATC-200, started the aluminum case trend that dominates enthusiast cases today (a whole, what, three years later). Until the PC60 and ATC-200 hit the scene, the aftermarket offered only standard issue beige or cheap and cheerful plastics. Now all the über-geeks go to LAN parties toting sleek aluminum cases, unfortunately usually ruined with big plexi-covered portholes brimming with neon light. Yeesh... kids these days. I wonder what kinds of sick mods they'd inflict on a Porsche. They'd probably line the rims with blue LEDs and etch a Quake 3 logo into the rear window.
The ATC-710 is quite a nice case, especially considering it's only around a hundred bucks (if you can find one). Even though only the faceplate is aluminum (the rest is ordinary steel), it looks as slick from the outside as any of its pricier all-aluminum brothers. The (all-aluminum) PC60 was over $200 when I bought it, though I think it's now down to $120 or so, which qualifies it as a bargain as well. One nice thing about the ATC-710 is the door over the drive bays; it's hard enough finding a case that looks good, let alone finding drives that match.
My other weird computer fetish is noise control. It really bugs me if my computers are louder than a whisper, mainly because I invested a lot in my stereo system and they share a room. The ATC-710 is noticeably louder than the old PC60, in spite of having a quieter case fan; the new case seems to resonate sympathetically with vibrations from both the hard drive and the power supply, which the Lian-Li did not. Hopefully I'll be able to solve that with some isolation pads from Directron.
I went with most of the rest of my company last night to see Don Box give a talk. The conference he was speaking at was called "XML Web Services One", and none of us are particularly interested in web services, so we were relieved that the subject of his presentation turned out to be a preview of Whidbey, the next major version of .NET (current ETA is second half of 2004).
The big news to me was anonymous methods. I had expected them to be much like Java's implementation of anonymous classes, only at the method level; in other words, I could write something like this:
public void SomeMethod() {
string label = "Foo";
this.Changed += new EventHandler(object sender, EventArgs args) {
MessageBox.Show(label + " detected change in " + sender.ToString());
}
}
and the compiler would expand it to something like this:
public void SomeMethod() {
string label = "Foo";
__anon_1_label = label;
this.Changed += new EventHandler(__Anon_1);
}
private string __anon_1_label;
private void __Anon_1(object sender, EventArgs args) {
MessageBox.Show(__anon_1_label + " detected change in " + sender.ToString());
}
While convenient, there's nothing really magic about what's going on here. It's just that the compiler would make up an opaque method name for you and move your method body there, while making copies of the caller's local variables for the method body to use. (OK, the code shown above wouldn't actually work because the same instance of __anon_1_label would be shared among potentially many instances of the anonymous method--let's just pretend.)
Well, it turns out that C# anonymous methods are not anything like the above. They're way better. They're real closures.
The difference between a closure and the above is that a closure is directly wired into the scope of the enclosing block of code. In the above example, it means that after SomeMethod() creates and registers the anonymous method, it could change the value of label and the anonymous method would "see" the new value when it gets called. Or, rather than just printing out a message, the anonymous method could change the value of label and the change would be reflected in the enclosing scope (assuming the enclosing scope is still around).
This opens up C# to all sorts of new styles of programming. For example, Ruby's beloved blocks and iterators will be possible:
List<i> list = new List<i>();
list.Add(1);
list.Add(3);
list.Add(5);
int total = 0;
list.each(new Visitor<i>(int i) {
total += i;
});
Console.WriteLine(total);
It's not as pretty as Ruby's syntax, but it's about as powerful and totally typesafe.
More fun with anonymous methods to come...
Lately I've been very interested in distributed components and services (let's call them "nodes") that "discover" each other on a LAN, and gracefully handle individual nodes going up and down. The Zeroconf initiative, which Apple dubs Rendezvous, tackles this problem by combining multicast messages and creative use of DNS (yes, that DNS). It seems to work well, as Mac types seem to really like iChat, which uses Rendezvous.
I've got some ideas about how to create a nice high-level C# binding to this. You should be able to take a marshal-by-ref object and just make one API call that says "make this available to everyone on the network."
I try to keep these entries strictly programming-related, but I can't resist commenting on the design of the new Power Mac. This is not a machine I would describe as "beautiful", unlike pretty much any other machine or peripheral Apple has produced in recent memory. I would describe it as impersonal, brutal, utilitarian. Especially after seeing pictures that aren't as varnished as the ones at apple.com.
Just admit it. It's not pretty. And yet, I still want one, and you probably do too.
The Power Mac G5 is to Apple what the Enzo is to Ferrari. The Ferrari Enzo is a distinctly un-beautiful car; all angles and protrusions, with none of the sensuality that Ferrari--and Italian design in general--is known for. Yet this is the most expensive Ferrari in history, and the one model to bear the first name of their founder.
Unsurprisingly, the Enzo's appearance was roundly criticized by the automotive press... but they all sang a different tune once they finally got a chance to get behind the wheel. The Enzo was designed to be a no-compromises performance machine, and that meant the design was dictated purely by the wind tunnel, not the eye of the beholder. Once you come to grips with that fact, it's not hard to see a different kind of beauty in this street-legal race car: an intense sense of purpose, an unswerving dedication to function over form. You don't need to look at the spec sheet to know this is the most powerful roadgoing Ferrari ever--it's spelled out for you in carbon fiber.
And so it is with the Power Mac G5. This is the first Apple in years that can run with the best Intel desktops. While I personally don't believe the benchmark numbers Apple has posted on their site, there is no doubt that it is a seriously fast computer. And thus, the big-metal-cage-o'-fans look works. "The better to cool my monstrous Power4-derived processors with, my dear."
The Enzo was designed by the wind tunnel; the Power Mac G5 is a wind tunnel. Impersonal, brutal, utilitarian... and very, very desirable.
Of course, I could be way off base. Maybe Ive and his band of elite designers actually think the G5 case is beautiful in the same way previous Macs have been. But I kind of doubt it.
(By the way, today's hot Mac comes with dual processors derived from the Power4, requires nine cooling fans, runs a UNIX-like operating system, and comes in a box that looks like a 4U rackmount. Do they still show that friendly, smiling Mac icon when the OS boots up? If so, they should change it to a pitbull.)
So, I never got around to building my Jini Jukebox, nor does it look like I'll ever find the time to. Instead I threw together LANMP3 [download], which is basically a rewrite of RemoteMP3, my original attempt at a client/server MP3 player.
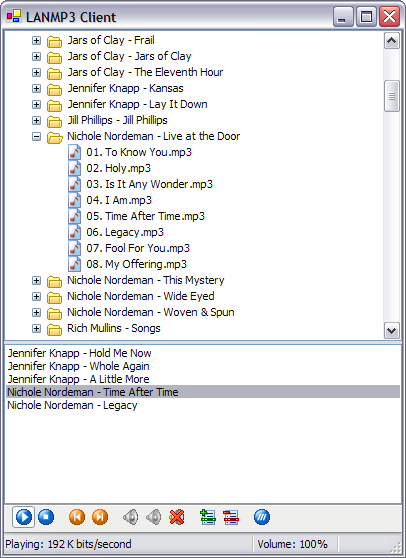
LANMP3 and RemoteMP3 let you have a music server running on your LAN that contains MP3 files and is hooked up to speakers, which you can control using any Windows machine on your LAN. This is not as nice as my Jini Jukebox pipedream, which would let you (sitting at any PC) direct any PC to play music streamed from any PC, but it does solve the problem of controlling my main workstation's tunes from my wirelessly-connected laptop.
The RemoteMP3 server was a headless Java program that wrapped the Java Media Framework, while the RemoteMP3 client was a Windows desktop application written in C#. They communicated using a custom protocol over TCP/IP sockets. For LANMP3, I decided instead to write the server as a C# program that wraps the Windows Media Player ActiveX control. The client is still a desktop C# program, but now it communicates with .NET Remoting (similar to Java RMI).
There were several problems with RemoteMP3. The worst was that JMF had problems playing many real-world MP3s that sound fine in Winamp or Windows Media Player; it would stutter or completely stop on probably one in fifteen MP3s in my collection. Furthermore, after it finished the last song in a playlist, it would make low-level pulsing static noises, as if it were looping the last second of the last song (just my guess). LANMP3 exhibits none of these issues, and as a bonus, WMP exposes a much simpler API than JMF (no surprise there).
Secondly, there was an unacceptable amount of latency between the RemoteMP3 client and server, despite the fact that I was using my own, very compact, direct TCP/IP socket protocol. The lag was on the order of *seconds*, even on a LAN, so there was definitely something screwy going on in my code. I never was able to track it down. On the other hand, .NET Remoting performs more than fast enough, and was much, much easier to work with. You have to know the particular incantations to publish an object as a remoting target, but once you do, it Just Works (well, usually).
LANMP3 binaries can be downloaded from my code page. Feedback is welcome.
Stumbled onto a pretty cool project at Microsoft Research: Polyphonic C#. Seems to be a set of extensions to the language that make it easier to write concurrent applications, and coordinate actions between various asynchronous threads. The introduction gives some illustrative examples.
You can see a list of other MS Research projects here... they are definitely not sitting still.
(Just for symmetry... here's a list of Sun Labs projects.)
One of the coolest things I've seen lately is Knoppix. Just download an ISO from their website and burn it to a CD, then reboot--voila, instant Linux desktop, no installation required. The entire Linux installation is already on the CD itself in runnable form, including drivers, window managers, applications, and anything else you're likely to need. It even comes with Java, Python, and even Ruby... all out of the box!
If I understand correctly, Knoppix won't touch your hard drive unless you do something to them. In fact, you don't even need a hard drive at all. For those who just want to try out Linux without having to repartition their hard drive or otherwise fudge with their perfectly tweaked Windows machine, this is about the least-invasive experience there is.
This isn't news for the Linux set... "live CD distros" have been along for quite some time, apparently, and range from tiny text-only installs intented for disaster recovery to full-on desktop setups like Knoppix. In fact, even I had heard of them quite some time ago, but never got around to actually trying one until now. It's the kind of thing that doesn't sound too exciting until you actually see it happen... like pausing live TV with TiVo.
Anyway, I highly recommend Knoppix. You've got nothing to lose but a blank CD...
Before I start the Ruby lovefest... regarding my previous post on Ruby, I found this tidbit from a FAQ entry:
Ruby's syntax and design philosophy are heavily influenced by Perl. It has a lot of syntactic variability. Statement modifiers (if, unless, while, until, etc.) may appear at the end of any statement. Some key words are optional (the ``then'' in an ``if'' statement for example). Parentheses may sometimes be elided in method calls. The receiver of a method may usually be elided. Many, many things are lifted directly from Perl. Built in regular expressions, $_ and friends, here documents, the single-quoted / double-quoted string distinction, $ and @ prefixes to distinguish different kinds of names and so forth.
I knew it! Is it just me, or is Perl at the root of all things evil!? ;)
All kidding aside, I have been very impressed with Ruby overall. It is as convenient as Python, but feels more coherent--some of Python's features kind of seem arbitrary or grafted on, as opposed to Ruby where a smaller number of constructs are more widely applicable.
I like that Ruby uses backquotes to `execute any arbitrary system command`--that's one Perlism that I wish all scripting languages followed.
I like blocks and iterators a lot.
I like how almost every statement returns some kind of expression.
I simply love eRuby. I don't know how many web scripting languages I've used over the years, but as far as basic syntax goes, I think Ruby-impregnated HTML is by far the best solution for me. I have been longing for a language that is fairly powerful (i.e. not a stripped down "templating language" like Velocity or CityScript), doesn't result in ugly code (see looping over collections in JSP), lets you do includes, and can (optionally) be used at "compile time" to create a static set of HTML documents.
(Note: This is a pretty unfashionable set of requirements these days--the trend is to move the power out of the hands of web developers and into dedicated logic classes, thus enabling better role separation. By taking the real code out of the HTML, you can hire (cheap) HTML developers who don't know how to write real code. Well, I know how to code, and I often need to create websites. Sometimes it's just really nice to be able to declare variables, perform arithmetic operations, and create and manipulate lists from right within the presentation tier. So keep your flaccid, stripped-down templating language outta my face.)
eRuby does all that and more. It is so wonderful that I'm having trouble expressing it in words.
It's just the little things. Say you have an array of images and want to filter out the ones that don't actually exist on disk. You can do this in one line:
<% imageList.delete_if { |img| File.exist?(img) } %>
Contrast that to, say, JSP:
<%
ArrayList tmpList = new ArrayList(imageList.size());
for (Iterator it = imageList.iterator(); it.hasNext();) {
String thisFile = (String)it.next();
if (new File(thisFile).exists())
tmpList.add(thisFile);
}
imageList = tmpList;
%>
or ColdFusion:
<cfset tmpArray = ArrayNew()> <cfloop index="image" list="imageArray"> <cfif FileExists(image)><cfset ArrayAppend(tmpArray, image)></cfif> </cfloop> <cfset imageArray = tmpArray>
This is just one example of Ruby taking one line where most other languages need five. Furthermore, it seems like the general problem of taking data and turning it into richly formatted HTML involves many of the kinds of operations that Ruby makes very easy:
It's almost as if Ruby was specifically designed to be embedded into HTML! (It wasn't.)
Also, I have found that static typing--while a huge boon in general--is less useful in this area, specifically because there is generally so much iterating and unmarshalling (from request parameters) going on, so you end up doing a lot of casting and parsing which defeats much of the static type checking anyway.
So anyway, there you have it. If nothing else, use Ruby for generating web pages. (I'm using erb as my eRuby implementation because it is small and portable.)
Having enjoyed my experience with Python so far, I decided to jump in the Ruby waters as well. I picked up Programming Ruby by Thomas and Hunt (of The Pragmatic Programmer fame); the full text is freely available online.
Ruby seems fine... not a whole lot different than Python at first blush. I like that it has stronger OOP support; an object's instance variables can't be accessed from outside of the object (you must use accessors), and there are formal notions of public/protected/private methods. Contrast this to Python's laissez-faire approach (i.e., no access control whatsoever). And of course, Ruby's iterators are very nice.
On the other hand, there seem to be an uncomfortable number of things you have to "just know". For example, there are quite a few predefined, global variables; one controls the default separator pattern for the String.split method, another holds the last line read by Kernel.readline and is used as the default for most print operations, another is the exception in a catch clause. Here's an example:
$, = ',' $; = '\t' while gets data = $_.split puts data.join end
This block of code converts tab delimiters to commas, but you'd have to know what $, and $; mean to make that connection.
In all fairness to Ruby, there always seems to be a "clean" way to do it as well:
while input = gets
data = input.split('\t')
puts data.join(',')
end
I'm also a little sketched out by how little you can rely on parentheses if you want to; to these Java-tainted eyes, it can make for some difficult-to-read code. When you see a comma-separated list of identifiers, you have to pay attention to figure out what's going on.
min 0, 100 // method call min 0, max x, y // nested method call a, b = x, max x, y // parallel assignment w/ method call rescue SyntaxError, NameError // catch clauses
Contrast this with Java, which forces you to use parentheses to on method calls and such. They cost you a few more keystrokes, but the resulting code is utterly unambiguous and easy to read. (Note that Ruby doesn't force you to leave off the parentheses; in fact, the book says you should use parens in all but the most trivial cases.)
It just seems like there's a little bit of Perl's "There's More Than One Way To Do It" thinking going on here, moreso than Python. Personally, that's not a mantra that appeals to me when it comes to syntactic details like where parens go, whether to use && or and, whether to make blocks with do..end or curly braces. I'd rather have an simple, consistent, easy-to-read language and sacrifice those freedoms.
You know what would be super fun? A distributed MP3 jukebox, using Jini.
Any machine on a LAN could run the Library service and/or Player service. Library would simply offer up a catalog of available MP3 files on that machine, and allow those files to be streamed to clients. Player would allow files to be queued up and played. All of this would be controlled by Swing clients from anywhere on the network.
With such a system, you could use your 802.11b-enabled laptop to have your HTPC start playing a song that is stored on a server in your basement. You'd never have to sync up your MP3 collection across multiple machines. And since it would all be based on Jini, it could all be very robust and decentralized, with no "central server" necessary. New Players and Libraries connecting to the network would be autodiscovered by everyone else.
All of this would be extremely easy to do; the Java Media Framework makes it easy enough to play MP3s, and the rest is just pushing bytes and messages around.
I'd love to build this, if only to give Jini a try. Oh well, tack it on to the end of the "To Do (Maybe)" list...
Encountered a particularly interesting little problem today. The requirement was to create a read/write locking mechanism for .NET that behaved according to these rules:
That's a description of a fairly standard read/write lock. What makes it more interesting is that this read/write lock must protect a resource across multiple processes. Thus, most of the standard .NET threading constructs are useless, since they're only good for coordinating multiple threads inside a single process.
Win32 does provide a few cross-process synchronization primitives, however: Mutexes, Semaphores, and Events. These can be used from .NET with relative ease (i.e., relative to many other interop chores). Between my friend John and me, we figured out that you can actually satisfy the requirements using only Mutex and Semaphore. It sure isn't pretty, though.
Start by picking a number that is slightly higher than the number of concurrent reads you can reasonably expect. In this case, let's say it's 100. We will create a global semaphore with this number of permits. We'll also create a global mutex. (The code that follows should be considered pseudocode: for illustration purposes only.)
// create or open global mutex
GlobalMutex mutex = new GlobalMutex("IdOfProtectedResource.Mutex");
// create or open global semaphore
GlobalSemaphore semaphore = new GlobalSemaphore("IdOfProtectedResource.Semaphore", 100);
public void AcquireReadLock()
{
mutex.Acquire();
semaphore.Acquire();
mutex.Release();
}
public void ReleaseReadLock()
{
semaphore.Release();
}
public void AcquireWriteLock()
{
mutex.Acquire();
for (int i = 0; i < 100; i++)
semaphore.Acquire();
mutex.Release();
}
public void ReleaseWriteLock()
{
for (int i = 0; i < 100; i++)
semaphore.Release();
}
Thus, having read lock simply means holding one of the semaphore's permits, while having write lock means holding all of the semaphore's permits. It's a little bit nasty and inefficient, but it seems like it should work.
Tune in next week, when we'll be creating a FIFO monitor using only bubble gum and a pocket watch. ;)
I first came to know the magic of thread-local storage through some old version of WebLogic--whatever was current in 2000. Anywhere in the EJB container, you could call User.currentUser() and with no more effort than that you'd get the instance of User that was responsible for the current request. Thus, two different threads of execution could call that same static method and receive different results. For a humble web developer who was just starting out with Java, this was rather mind-blowing.
Older and wiser now, there's no mystery to thread-local storage; it's rather a simple mechanism if you think about it. All that's happening is a mapping between threads and values. Java exposes it via the ThreadLocal class:
// Java code
class User {
// whatever instance members...
private String getUsername() { ... }
private static ThreadLocal currentUser = new ThreadLocal();
public static User currentUser() { return (User)currentUser.get(); }
public static void setCurrentUser(User user) { currentUser.set(user); }
}
At the beginning of a request you'd just have to make sure to call User.setCurrentUser(user), and for the rest of the request's lifetime you could get access to that user using User.currentUser(). (For the moment, let's forget about thread pooling and the problems that might create.)
Basically the ThreadLocal acts like a hashtable, except you don't get to specify the key in the get/put methods, because the key is always the current thread. (In Sun's JVM, it isn't actually implemented this way; each Thread instance has an area to put thread-local variables. Makes for easier cleanup when the thread dies. For the purposes of this discussion, though, it makes little difference which way it's implemented.)
If you're familiar with Java's thread-local storage already, none of the above is news. What you may find interesting, though, is one of the mechanisms C#/.NET offers for thread-local storage:
// C# code
class User {
// whatever instance members...
private string GetUsername() { ... }
[ThreadStatic] private static User currentUser;
public static User currentUser() { return currentUser; }
public static void setCurrentUser(User user) { currentUser = user; }
}
See what's happening here? Simply by adding the ThreadStatic attribute to the static member, every access or assignment of that field gains thread-local semantics. Now someone please explain to me how this actually works!? My only guess is that the compiler and/or the CLR have specific knowledge about the ThreadStatic attribute and handle themselves accordingly. If there's a way to do anything like this yourself using user-defined attributes, it's beyond my (admittedly rather limited) imagination.
Assuming that I'm right and the compiler/CLR have knowledge of ThreadStatic built in, this kind of typifies the difference between Java and .NET (and I guess, Microsoft in general). The Microsoft approach results in a more convenient, concise syntax, as it saves a couple of explicit casts. However, it also involves a "magic" attribute that only has its powers because of specific support in the compiler/CLR. The Java approach requires no language or runtime support; the whole notion of ThreadLocals exists at a higher layer (you can see this for yourself in the JDK's Java source).
After almost seven months of programming in C# full-time, I'm still finding new language features all the time that surprise me. A couple of weeks ago, it was the "add/remove" keywords that let you override the += and -= operators for events. Yesterday it was ThreadStatic. C# may look a lot like Java on first glance, but it is a significantly larger language with more "magical" features. Whether that's good or bad is up to you; I, for one, think small is beautiful.
One last thing. If ThreadStatic does have compiler/CLR support, shouldn't it really be a keyword? That way at least it's obvious that there is something very un-attribute-like going on (the same could go for a couple of other magic .NET attributes, like Conditional and... well, I can't remember the others at the moment).
// pretend C# code private threadstatic User currentUser;
I thumbed through most of Essential ASP.NET by Fritz Onion this weekend. It's a great read; not at all dumbed down in the way that many Microsoft-technology books seem to be (e.g. ones with "Step by Step" or "Teach Yourself... In 24 Hours" in the title). I'm really impressed with Addison Wesley in general; I think almost all of my favorite tech books are AW.
I really had ASP.NET pegged wrong; it's quite a different beast than I thought. You're not at all tied into the Web Forms model, though they push you very hard in that direction (especially if you use VS.NET). Design-wise, ASP.NET probably owes more to servlets/JSP/JSF than to "classic" ASP.
JSP pages compile to Java classes; ASP.NET pages compile to .NET classes. Servlets let you change configuration/deployment properties via web.xml; ASP.NET lets you do the same with web.config. Servlet containers automatically expose Java classes stored in /WEB-INF/lib and /WEB-INF/classes; ASP.NET exposes .NET DLLs stored in /bin. More recent versions of the Servlet API allow you to pre- and post-process requests with HttpFilters; ASP.NET gives you HttpModules. Contrast this to ASP which (to my limited knowledge) was fully interpreted, had most settings stored in IIS, and interoperated mostly with COM.
ASP.NET's code-behind feature is rather nice; I don't think there is anything quite like it in JSP just yet. It gives you a very clean physical separation between the presentation and UI logic, yet keeps them very tightly coupled--so tightly coupled that the compiler can do a decent job of detecting when the page and the code are out of whack. Every aspx page compiles to a subclass of System.Web.UI.Page; by enabling code-behind for a page, you are basically directing that page to extend a specific subclass of Page instead of extending the generic Page class. So any code that you write in the code-behind class is available in the aspx page, and (through some reflection) your code also has direct access to the controls in the aspx page.
Boy, I did a really poor job of explaining that. That's why Fritz Onion is an author and I'm not...
The bottom line is, ASP.NET looks like it can go toe-to-toe with Servlets/JSP on most fronts--they've basically "copied" most of the ideas from the Java camp, and then added Web Forms. Not that the Java camp won't be there soon; the JSF spec is in public review and there has been a reference implementation available for a while now. Now that I fully grok Web Forms, I'll have to take a second look at JSF...
I think it's very interesting to see how various groups of programmers tackle the general problem of creating dynamic websites. (Pardon the sweeping generalizations that follow.)
I cut my teeth on ColdFusion, where you just inject code into the HTML. At least in the early ColdFusion days, most CF developers were web designers for whom CF was their first programming language, so this was a very natural model for them.
I've spent the last few years in the Java camp, where most people subscribe to the "MVC" model where a controller servlet (C) maps requests to business logic classes (M) and presentation templates (V), usually using XML directives to tie the whole thing together. Java programmers tend to think all of the components they write are pluggable and reusable, and that XML is a perfect "glue" language because modifying XML is somehow cheaper than modifying source code.
ASP.NET (and Java Server Faces) bring the paradigm of event-driven UI programming to web apps, allowing Visual Basic style point-and-click programming. (Unfortunately I can't speak from experience here, since I haven't done any ASP.NET programming nor do I know any ASP.NET programmers; but I'm doing a lot of Windows Forms stuff in C#, and it's clear Microsoft worked really hard to make web-based programming the same way.)
Python folks are a peculiar breed. I'm still very new to the language and the community, but in general Python programmers seem to be very clever. Zope looks like a pretty clever framework. I've only spent a couple of hours browsing the docs, so the following may be completely inaccurate, but here goes.
In Zope, you basically publish object graphs. A Zope URL like http://myserver/store/browse/bycategory?categoryid=1 probably maps directly to (zoperoot).store.browse.bycategory(categoryid). This is the first time I've personally heard of a direct containment metaphor for mapping objects to URLs.
Of course there are ways to override this behavior, but this is the basic mapping mechanism. Notice that request parameters are automatically parsed and passed in as arguments. Pretty nice. By default all the arguments are marshalled into strings, but you can specify different marshalling behavior by using special suffixes for your form field names, e.g. <input name="age:int"> will be automatically marshalled into an integer.
I think both the URL mapping and the argument marshalling are really nice; I find them intuitive and concise. However, I can't help but wonder how great it would be if the language for writing these published items was C#, not Python. Static typing and attributes could be great assets here:
[Security(RoleRequired="customer", OnDenied="/login.htm")]
public class Store : ZopeObject
{
// this could be a property or method if you prefer
public readonly ZopeObject Browse = new Browse();
[DefaultPage] // in lieu of having zope's "index_html" magic method name
public Response StoreHome()
{
// ...whatever...
}
}
public class Browse : ZopeObject
{
public Response ByCategory(
[Label("Category ID"), Required] int categoryId
)
{
// ...whatever...
}
}
In this example, the security and validation are totally declarative, and the marshalling of the argument is implied by the type. And rather than having to maintain a separate XML file, it's all right here.
(Unfortunately, I have a feeling that writing any kind of web framework that targets .NET will be a losing battle. Microsoft programmers won't use it because it's not Microsoft's recommended framework. Non-Microsoft programmers won't use it because it's .NET.)
Anyway, I haven't even started scratching the surface of Zope. I'll write about other interesting features as I encounter them.
Mozilla Firebird is the browser I've been waiting for.
I've always wished for some of the features Opera and/or Mozilla users have enjoyed for some time: mouse gestures, typeahead link search, easily searchable bookmarks, good PNG support, etc. However, for me, all of those new whizzy features were outweighed by the degree to which Internet Explorer keyboard shortcuts were wired into my head. Most of those shortcut keys had equivalents in the alternative browser, but I found them hard to get used to. Besides, both Opera and Mozilla seemed slower (in starting up) than Internet Explorer on my machine.
Fortunately, Firebird addresses every one of my complaints while adding some of the most useful features that Mozilla has and Internet Explorer lacks. For the most part, Firebird's keyboard shortcuts are a strict superset of IE's--they even included the obscure but incredibly useful Ctrl+Enter (adds "http://www." and ".com" to what you have typed in the address bar). But all of the fun new stuff is either present in Firebird or available via Mozilla extensions, which are useful, small, and trivially easy to install.
Anyway, I've switched my default browser to Firebird. It really is that good, even compared to Internet Explorer running on Windows.
Started playing with Python a little bit tonight. After hearing so much about it on Artima and various weblogs, I thought it was finally time to see what all the fuss is about.
So far I've only gotten around to writing a couple of toy procedures, but I am already starting to have an appreciation for how easy and natural the language syntax is. As it says somewhere in the docs, Python looks a lot like pseudocode. I actually like the significant-indent style; I never noticed how ugly curly braces were, until now. Also, the interactive shell is fun--I think Python may be worth learning just so I can interactively test my Java classes using Jython.
I want to spend a lot more time with the language before coming to any solid conclusions, but I couldn't help thinking about whether I was going to be able to get over the lack of static type checking. I think there are a lot of programs, even large ones, that really aren't going to benefit that much from static type checking, but many others where you really want to have it.
Software projects with sprawling "palaces of abstraction", especially where said abstractions are constantly in flux, certainly benefit from static type checking. Most of the companies I've worked for in the past three years have had mostly this kind of situation; a B2B bond trading marketplace, an online/offline consumer rewards program with hundreds of nationwide retail partners, and now--well, I can't talk about my current job, but the subsystem I'm writing definitely fits into that category. All of these codebases had hundreds or thousands of classes, featuring deep class hierarchies and heavy use of interfaces. All were constantly being debugged, tweaked, refactored, gutted, rewritten, and rethought by swaggering young coffee-chugging developers. It's hard for me to imagine maintaining that kind of code without a type-checking compiler to keep things on the straight and narrow.
On the other hand, many of the projects I worked on more than three years ago seem like they would have benefited from Python. I would have been quite comfortable implementing small- to medium-sized content management systems, or community websites like the Action XChange, in Python. The new photo album webapp I recently lauched probably would have been finished faster and with less code. These are situations where, for me, it's hard to imagine needing palaces of abstraction.
Anyway, I'm looking forward to exploring Python further and seeing what all the hype is about. It's hard to imagine any language living up to the kind of praise some programmers have been lavishing on this language, but I'll give it the benefit of the doubt...
I can't talk about what I'm doing at work... so I thought I'd post what I have cooking in terms of side projects. Well, actually I'm not putting very much time into extracurricular coding just now; I'm busy being a newlywed. But if there were, oh, 40 or 50 hours in a day, here are the things I would be working on.
There you have it... my current list of woulda's, shoulda's, and coulda's.
Finally got all of the wedding pictures online. They're posted at http://www.amyandjoe.org.
The site is all Java servlets and JSP over MySQL, on a TurboLinux box my cousin and I run. I may write a C# client for administering the site (drag-and-drop adding of images... ohhhh yes).
I've always associated GDI programming with user interface widgets. It only very recently occurred to me that these same methods that are used to paint pixels on the screen, can also be used to manipulate image files. This fulfills a long-running dream of mine, to be able to manipulate .gif and .jpg files the way most programmers can manipulate .txt or database data.
Last weekend I was able to write a short C# program that recurses through a directory and resizes any .jpg's it finds there to fit within 600x600. Then I got a little more ambitious and added a routine to make thumbnails: resize to within 100x100, expand canvas to 120x120 with a white background, and overlay a specified .gif file. The result:

(Notice that the thin gray border is part of the image... that was the whole point.)
All this with only a few commands--Windows' own graphics libraries do all the work. The same API provides the ability to draw text in any font/style you can imagine. So it'd be easy to create, for example, a dynamic headline .gif generator.
The only fly in the ointment is that .NET doesn't seem to do a very good job of reducing 24-bit images to 8-bit--it just uses a fixed 8-bit palette instead of choosing 256 colors from the image--and you pretty much have to work with a file in 24-bit to get anything done. So in practice, the useful (color) output formats are 24-bit PNG and JPEG. At least you can specify the compression ratio on the JPEG.
Anyway, none of this is news to experienced Windows programmers. But as someone who not too long ago was "just" a web developer, I'm pretty pumped.
// not shown: insert new bid into bid table
bidders = query("SELECT ... ORDER BY maxBid DESC, bidTime ASC")
winner = bidders[0]
runnerup = bidders[1]
x = winner.maxBid
y = (runnerup == null) ? MIN_BID : runnerup.maxBid + BID_INCREMENT
return min(x, y) My poor Mandrake Linux box--formerly hush.joecheng.com--was hacked into this week. Whoever it was decided to mess with my config files and damn if I know how to fix 'em (other than a clean format and reinstall). I'm not sure exactly how they got in, but I haven't installed any updates or patches since I set the thing up, so I'm sure there was plenty of fertile ground to exploit. Good thing I wasn't really using the box for much, and all my data was pretty easily recovered.
By the way, I don't think I like Mandrake. I'm no expert on Linux distros (or any other *nix topic) but it just feels like an old version of Red Hat. So if I decide to reinstall Linux it'll be Red Hat 9... all the hipsters seem to like it.
Strangely enough, this is also the week my server xenia.mit.edu, which has been rocking pretty steady for seven years (with occasional upgrades), bit the dust; I think it's a burned-out power supply but haven't had a chance to give it a full inspection.
In both cases, no data was lost, and assuming the repairs go well on xenia I'll have not one but two clean servers to toy with. Hmmm... might be time to start playing with Jini...
The code behind whateverblog used to be my own JSP template that used a POP mailbox as its storage. I would just compose an e-mail and send it to that specific e-mail address and it would show up as a new entry on the blog. It was quick and easy to get it running--easier, at least, than getting my Linux box to accept MovableType--but editing past entries was impossible and runtime JSP support became a requirement.
Now I'm using CityDesk by Fog Creek Software, which is basically a very friendly, very useful HTML template preprocessor. It's a little frustrating to not have a full programming/scripting language at my disposal, as CityDesk's CityScript doesn't even have variables or basic arithmetic operators. However, CityDesk does force separation of content and presentation in a very natural way, and the resulting static HTML files require no runtime support. You also get one-touch deployment, and all of the site source (including all binary files) are contained in one easily transportable file.
If CityScript ends up being too restrictive, I'm going to check out X-Code. Seems like it should hold me for a while though.
Well, the wedding went off without a hitch and the honeymoon was fantastic. We've even managed to move Amy into my tiny apartment since we got back. Married life is good!
I just started reading Out of Their Minds: The Lives and Discoveries of 15 Great Computer Scientists by Cathy Lazere & Dennis Shasha. It's an easy read, and they've chosen some quite interesting people, including John McCarthy (inventor of Lisp), Alan Kay (inventor of OOP), and Donald Knuth. It's interesting to learn about the personal and professional influences that led them to their breakthrough achievements; most of their key insights didn't come "out of the blue", but rather grew out of trying to solve specific problems that annoyed or intrigued them. Anyway, definitely recommended for those who are interested in some light history.
I populated a mailbox with 100,000 messages and accessed it using the new POP server and I've gotta say, it was pretty darn snappy. The only perceptible pause is on opening the mailbox, I would call it 500 to 1000 milliseconds (I didn't time it though). When you consider the latency you'd encounter in a typical client/server scenario... well, I think it's safe to say the e-mail server will be Fast Enough under reasonable (and often, highly unreasonable!) circumstances.
Next on the to-do list is making the RFC822 header parser ignore parenthesis-style comments, and figuring out how authentication will work. And I have to do some refactoring on the mailstore code, now that the ideas have crystallized in my head. Wasn't it Brooks who said something like "Plan to build it twice; you will anyway"?
For a single inbox of approximately 100,000 "average-sized" e-mails, the metadata takes 3.4MB on disk. The real size of the messages is 541MB, but due to a 4K sector size and the fact that I am storing each message individually, the on-disk size is 732MB. I knew there would be inefficiency doing it this way, but paying 35% of the original file size is way higher than I expected. But really, who cares--hard drive capacity is cheap, and the size of e-mail messages stays relatively constant (or if it tracks anything, it's bandwidth).
| Task | Time | Grows linearly with |
| Open mailstore | 60 ms | mailbox count |
| Open mailbox containing 100,000 messages | 1462 ms | message count |
| Add 30,000(!!) messages to mailbox* | 42761 ms | number and size of messages to deliver |
| Get mailbox message count (total and unseen) | 40 ms | message count |
| Close mailbox | 1793 ms | message count |
* This assumes 30,000 messages sitting in an INBOUND directory, one file per message. The operation for each message involves getting the length, getting the timestamp, creating a new message metadata object, and moving the message file to the mailbox directory.
Anyway, these times are from an IBM ThinkPad T30 laptop, P4M 2.0GHz. I believe the hard drive is of the 5400RPM 60GB variety, but it doesn't feel any faster than any of the 4200RPM notebook drives I've used. In any case, the average new desktop IDE drive should score much better times.
I think this level of performance is more than sufficient, at least with clients like Outlook, Outlook Express, and Mozilla that want to download all the message flags as soon as they open a mailbox. Response times with those clients, for very large mailboxes, will be completely dominated by the time it takes to download all of those flags.
What is really scary is how long searching will take unless I do some far, far more drastic indexing. I'm going to do a little more research on how O/OE/M do searches before I commit to that, and even then optimized searching may not be a part of the first release.
I thought the only things I needed JavaMail for were to retrieve mail from POP mailboxes and to parse RFC822 headers. I was able to implement both of those myself fairly easily. After reading the RFCs on MIME yesterday, JavaMail is back in--it's just too much work right now to write my own MIME parser, especially since the RFC is almost impossible to read. It's something I'd definitely like to revisit before I'm done, but for now I think my time is better spent on other aspects of the server.
I also got an answer about header fields and body structure. According to the one or two responses I got on comp.mail.imap, I don't need to cache header fields (they're cached on the client side by most modern clients) and only need to cache body structure because Netscape Communicator does partial fetches of body parts. I think I'm going to just cache the most recently used body structure for each session, and throw out the cache when the session closes.
I did get a couple of hours of coding in on Saturday morning, and it looks like message metadata persistence is almost complete. Another couple of hours should see metadata persistence at the mailstore/folder level working. I think that's all I need to start testing the scalability of the mailstore. It'll be interesting to see how all of my assumptions pan out when the rubber meets the road. (Well, interesting for me. You all probably couldn't give a lick until it's "5 - Production/Stable".)
I haven't decided yet whether to support user-defined flags, and I don't know whether it's important to cache header fields and body structure--I've posted a message to comp.mail.imap, hopefully someone there will help me out. Hate to say it but they seem like a little bit of a scary bunch--perhaps years of dealing with non-spec-compliant clients and servers has made everyone just a little bit jaded.
I also got a chance to test the code that fetches mail from POP and queues it to the correct mailstore... it works great! I'm really glad I decided to write my own POP client for this purpose instead of relying on JavaMail. I rather value the efficiency I'm getting, rather than trying to abstract away the mail implementation as JavaMail does.
Also took a moment to comb through the Apache James mailing list archives and wiki to see where their IMAP efforts are. It seems that they are actually on their third ground-up implementation of IMAP, and there isn't much indication that this time around will be more effective than the last two. It may be that there are fundamental differences in the way the James mailstore is implemented versus the way IMAP needs it to work. In any case, I think the IMAP protocol is difficult enough to implement without trying to graft it onto an already-working POP/NNTP server--much better to start with a ground-up IMAP implementation and then add other protocols afterwards.
While that would have been nice, I would have had to make some pretty difficult compromises. The biggest one is, I'd have to pretty much not hold anything in memory for longer than absolutely necessary; since IMAP sessions are long-lived and mostly idle, it'd be very easy to run out of memory even if most logged-in users are not actively doing stuff. I'd probably not want to do Java serialization of metadata then (Prevayler or no), instead creating my own metadata file format (or using one of the ones out there) and hitting the disk for every operation.
Either that, or just use a database. That would not be my first choice though, because the main goal here is simplicity and ease of installation. (If in the future I decide to revisit this decision, a possibility may be an embedded Java database--they're out there, right?)
By targetting the server at small groups of power e-mail users, I can make it *extremely* responsive (except for complex searches... heh) at the price of having, say, a 2-10MB memory footprint per session. Anyway, sites that are big enough for that to be a problem probably have the expertise to use Cyrus or the money to use Exchange.
Oh, I've also decided to add a POP server as sort of a bootstrap, so I can start using Poorman for my own mail as soon as the mailstore is finished rather than waiting for the whole IMAP protocol implementation to be complete. (POP really is a pretty ridiculously simple protocol... wrapping the mailstore with it should take maybe an hour, including all optional commands.)
Anyway, it's all shaping up quite nicely so far. Once the mailstore is done I'll have to look into putting up a public source repository--probably not Sourceforge, though; I can't deal with cvs.
What the heck!
If I want to support those users it looks like I'll have to, at the very least, only hold metadata in memory for selected mailboxes. If a single mailbox has 1,000,000 records, a (very) rough estimate would be 40MB of RAM simply to hold the e-mail metadata in memory. Luckily, if ten users all have the same mailbox open, it only counts once, not ten times.
One encouraging point is that given a reasonably fast disk subsystem, the serialization/deserialization should not take terribly long. On an unloaded server, reading and deserializing 100,000 messages worth of metadata could take as little as 300ms using a midrange Pentium 4 with any modern ATA hard drive. (I've only tested so far on my laptop, whose hard drive is much slower than even the slowest of today's desktop drives.)
Furthermore, as expected, the metadata searching is blazingly fast. On a P4-M 2.0GHz, checking for the presence of 5 flags across 1,000,000 messages takes much less than 100ms. Unfortunately, doing a fulltext search against those same 1,000,000 messages will be impractically slow unless I add Lucene to the mix. Anyone know if people out there actually do server-side IMAP searches?
I was also able to wire up and test the POP3 retrieval and mail storage mechanism (i.e. calling out to a POP3 server, fetching the messages, and adding them to an IMAP mailstore). It works flawlessly--as it should... POP3 is a simple protocol and my mailstore is a simple implementation.
Still, good to know that "all" I have left to do is add Prevayler metadata persistence, implement the IMAP protocol, provide user management tools, come up with an easy install/configuration tool, add server side mail filtering... ;)
I hate to say it, but it's not that transparent. By that I simply mean that Prevayler will most definitely make you write your classes in a certain way, following a certain idiom. Sure, Prevayler doesn't require a bytecode enhancer, and it doesn't require you to extend a certain base class, and it doesn't require you to wrap proxies around everything. Still, the fact that your "Business Objects" have to be "deterministic", and any use case that will cause any state change in any Business Object must be called via a fully encapsulated Command object, presents its own quite unique set of design forces on programs that have a lot of interaction with the outside world.
Consider, for example, the example of creating a new mailbox (or folder) for an existing user. Three things need to happen:
Originally, I had these three concepts wrapped into a single MailStore.addMailbox(String newName) method. But when I decided to use Prevayler to persist all metadata, such as the hashmap of mailboxes, and tried to turn this method into a CreateMailbox Command class, I realized that the first two steps couldn't be part of the command. It may not be obvious to all why this is so, so here's a detailed example:
Let's say that at midnight, a full snapshot A is taken. Between midnight and 9:00AM, many commands are executed and logged, including several CreateMailbox calls. Let's refer to the state of the world at this time as B. At 9:01AM, someone hits Ctrl-C and then restarts the server. Now, as soon as Prevayler starts up, all of those commands will be executed again against A in an effort to bring the world back to B. But it won't work, because the state of the filesystem is not part of A--it's part of the external environment.
In other words, re-executing the command log must operate only on the state of A and must bring it to a state precisely equal to B. In an application like an IMAP server, where filesystem changes and metadata changes are often tightly coupled, this leads to a slightly un-OO dichotomy between the two. The metadata management will happen in one package through one set of interfaces, and the filesystem management will happen in another, and only the layer above guarantees the two will be executed together correctly.
I was wondering if maybe one way to handle this would be to let the Command know whether it was being called for the first time or during recovery mode (or whatever they call rolling the changes into A). But that approach would definitely have its own set of pitfalls and probably lead to the most insidious bugs the world has ever known. :)
To put all this in perspective, though, I'm certainly still better off than using an RDBMS or plain Java serialization, in terms of both performance and simplicity. I'm very impressed by the sheer elegance of Prevayler's design and it's nice to know the performance will be orders of magnitude better than it needs to be. Yesterday was just a reality check for me--Prevayler is great, but it still makes its own set of demands on the developer, and those demands can be more significant than they first appear.
For all that Prevayler promises, I'll happily accept those demands. And for projects where external resources aren't tightly coupled to business objects, or a command architecture is already in place (like Struts), the price could be very low indeed.
I think the IMAP server is going to use Prevayler as the persistence mechanism for message/mailbox metadata. RFC2683 encourages the server developer to make metadata querying very responsive, while searching against content (i.e. message header values and message bodies) can be much slower. That's nice because the metadata tends to be very small and well-structured and the content tends to be large and a mess.
The messages themselves will be kept in plain-text, each in their own file, with the filename being derived from the message UID that IMAP requires you to maintain. So even if your installation of Poorman kicks the bucket, your messages are fully viewable. Heck, if I give those files the .eml extension, double-clicking them will open them right up in Outlook Express! :)
Anyway, each mailbox (or each user... not sure yet) will have its own prevaylent system (an analog to "database"). So at time of folder selection (or user login), whichever, the prevaylent system will be initialized (e.g. serialized snapshot read into memory) and whenever the user leaves the folder (or logs off) or calls the CHECK command the command log will be rolled into the snapshot.
Since I will make sure the metadata has a very very small footprint (for example, implementing message flags as bitmasks on an int or long), and only one prevaylent subsystem will be active per user at a time, memory usage should be perfectly acceptable. For example, loading up 10,000 messages' worth of metadata (that's a lot of messages for one folder, don't you think?), at say 50 bytes per message, would conservatively take on the order of 1MB. That's more than acceptable for me, considering the phenomenal metadata querying performance that ought to result.
I was also a little concerned that the snapshot deserialization (i.e. prevaylent subsystem starting up) that will have to occur while the system is live (as opposed to during startup) would be a problem. If it does take on the order of seconds to load up each mailbox it may be necessary to load all the mailboxes for the user at login time. I guess, as always, it's the time/space tradeoff.
One thing I have not yet considered is how and when to deal with incoming messages. If snapshot deserialization is a factor I could store them in a queue until the user logs in next time. Once the snapshot is loaded it should be almost instantaneous (in terms of user-perceived system responsiveness) to process even hundreds of e-mails.
Suh-weet. ;)
Right now I'm leaning towards use a filesystem-based scheme where IMAP folders are represented by directories, and each message gets its own text file (named by UID) containing only the raw RFC822 message. All of the flags for both the folder and its messages could be stored in one data structure that is persisted using Java serialization.
I'm not sure yet how this approach will scale when folders start holding many thousands of messages. And if many mail messages are very small, then it starts being significantly wasteful of disk space (well, maybe not "significantly" when you consider the size of modern hard drives).
I'm trying to resist getting a database involved, but I have to admit it would make a lot of things easier...
*Yawn*... one to sleep on, perhaps.
The two major ones, UWash and Cyrus, don't play on Windows and require you to have a separate Mail Transfer Agent (sendmail) installed and configured. Well, I'm not up to the task of setting up an MTA on my Linux server (it's pretty amazing that I even have a Linux server), and I imagine there are many other people out there like me.
So I'm writing an IMAP server in Java that hopefully will be so easy to install and use, anyone can set it up and run it off their home machine. (The DynDNS part of it will actually be the harder part to get newbies through.) I'm calling it the "Poorman's IMAP Server" because it's not targeted toward large, production environments; it should be high performance but I'm not going to spend a lot of time worrying about >20 user environments. That energy will instead be diverted to making it correct, configurable, flexible, and easy to use.
The default mode will be "piggybacking" off a POP account, so rather than requiring an MTA to be installed you'll need to have a POP account somewhere. For users who want to set up a standalone server, this may sound like a backward approach compared with integrating with an MTA/mailstore, but I'm guessing this approach will in fact be much easier for many users. This is especially true on Windows where there don't seem to be any mailstore standards, but a plethora of free SMTP/POP implementations.
Another thing that is nice about piggybacking off POP is that the machine that hosts the IMAP server doesn't necessarily have to have stupdendous uptimes. If the only "server" you have access to is your home machine, which is connected via a sometimes-flaky DSL line, then you don't have to worry about e-mails getting bounced back to their senders because your DSL is down. Instead, your ISP's POP machine, which should have much better availability, will store the message for as long as it takes for your IMAP server to get back online. As an added bonus, you don't have to change the e-mail address you've been using.
I realize you can use fetchmail or something similar and enjoy the same benefits. But then, that is one more piece of Windows-unfriendly software to install/configure.
Feedback is welcome. Thanks...
After a few years in web development I became frustrated with the cruftiness of front-end web development. It was especially tough for me in n-tier environments like J2EE, because the potental elegance of the business logic classes contrasts so starkly with the hackishness of JSP.
It's hard to explain what I mean when I say "cruftiness" and "hackishness". It's not just about code reuse. I think there is something fundamental about the way web front-ends need to run wide and shallow--many different code paths (i.e. pages or form targets), each of which is usually very short and uninteresting--as opposed to business logic, which often (not always) tends to run narrow and deep.
I've long since given up on coming up with a clean presentation layer development model.
Instead, my goal is to come up with a model that discourages the sprawling web/JSP/presentation layer from corrupting the abstract/Java/business logic layer. Let's start by examining some fundamental tasks your typical web app must perform (not an exhaustive list):
The idea behind xcc is that all of these "up-for-grabs" items need to be handled in a way that recognizes the sprawling nature of presentation layers while protecting the biz-logic layer from that sprawl. There are three fundamental tenets:
The first tenet is that the classes at the business logic layer should be completely divorced from the concept of HTTP, stateless requests, etc. Not only does this mean that you'd never pass HttpServletRequest (or HttpAnything, for that matter) into a business logic method; it means your business logic objects should not have to implement any presentation-level interfaces or extend any presentation-level classes, period. (This is specifically in response to the idea of using Struts Action classes to house your business logic--yuck.) This also implies that there should never be a one-to-one correspondence between web forms and business logic classes, unless it happens incidentally.
The second tenet is that many jobs are best expressed declaratively (including the above-mentioned parsing, validating, security, exception handling) but the most important job--actually invoking the business logic--needs to be expressed imperatively.
The third tenet is that to the extent possible, "compile-time" checking should be used to determine whether any errors have been introduced.
Lesser tenets: The system should be easily extensible. It should be easy to use. It should treat developer productivity as a high priority.
So, enough theory. In practice, xcc can be thought of as a layer of XML that serves as the glue and the fence between your JSP pages and your Java objects. It bears a little superficial resemblance to Struts' struts-config.xml, but the purpose and implementation are miles apart. Whereas the goal of struts-config is to do just enough work to hand off the request to an Action class, the goal of xcc is to get all of the dirty work out of the way and then invoke your business logic directly.
For example, if you have the following business logic classes...
public class User {
public User(String firstName, String lastName, java.util.Date birthDate);
...
}
public class UserManager {
public static void createUser(User user);
}
...and the following form...
<form action="/registerNewUser" method="POST">
<input type="text" name="firstName">
<input type="text" name="lastName">
<input type="int" name="age">
</form>
...then you might have the following chunk of xcc XML:
<target path="/registerNewUser">
<!-- Parse some request parameters and convert
them to strongly typed xcc/Java variables, and
also do some validation -->
<params>
String firstName : required
String lastName : required
int age : required, min=1, max=130
</params>
<java import="java.util.*,com.joecheng.user.*">
// use a calendar to use age to calculate approx. birthdate
Calendar cal = new Calendar();
cal.add(Calendar.YEAR, age * -1);
// just do it
User user = new User(firstName, lastName, cal.getTime());
UserManager.createNewUser(user);
// save it on the HttpSession for later
session.setAttribute("user", user);
</java>
<forward page="/registerThanks.jsp"/>
</target>
The actual XML vocabulary that xcc understands is not only not finalized, but completely user-definable. I'll demonstrate how in a future post, but for now, recognize that you can define your own custom XML tags to do whatever the heck you want, and in the meantime you have the ability to write inline Java code. To a reasonable extent, all of this is statically checked (note that the compiler in this case is not javac, but an xcc tool); so using the example above, if you changed the <params> chunk such that firstName was no longer a String, then the call to User's constructor would cause a compile-time error.
The end result is that your Java code stays clean, the ugly/repetitive tasks are at least somewhat cleaner (because they're declaratively defined in XML), and you can have a certain degree of confidence that at least the XML and your Java code is in sync. (Note that there is NO compile-time protection against the actual HTML forms changing. If you have any ideas on how that could work, let me know.)
I actually have this all working, but not yet packaged in such a way that I'm comfortable releasing it. If you're interested, contact me and stay tuned.
{kind=link}